
 Vishal George Palliyathu, Manju Joseph, and Bijo Jessy Francis, Cisco
Vishal George Palliyathu, Manju Joseph, and Bijo Jessy Francis, Cisco
March 15, 2021
The Git-Markdown-HTML ecosystem has had many early adopters in the Technical Communication discipline and is often a big boon for the nimble-footed start-ups who need to get their mandatory documentation through the door, with fewer hassles. The trio has the appeal of being open-sourced and setting up the ecosystem is adventurous enough in its own right.
DITA vs Markdown
Though Markdown (MD) and DITA had both started off during the mid 2000s, DITA has had a steady growth and adoption in the decades since, while Markdown gathered momentum suddenly over the last few years. Markdown’s sudden adoption among the Technical Communication tribe was largely due to Git’s adoption among a growing array of cloud-based products.
The DITA standard has been a steady presence in the industry and has proven Return on Investment along with single-sourcing capabilities and a robust content-reuse mechanism. However, DITA’s large learning curve and its investment-heavy but robust publishing ecosystem were major deterrents that forced cloud-based product development teams to look for a simpler infrastructure.
Markdown fills in this niche gap well. It has a significantly lightweight mark-up language, minimal syntax, and the publishing pipeline (into HTML) can be established in a fraction of time and cost when compared to the DITA-PDF/DITA-HTML models. However, Markdown offers none of the incentives much needed by mature enterprises. Content reuse and single-sourcing are salvaged for ease of authoring and quick deployment.
The lure of continuous publishing
Early cloud-based products and solutions had minimal development life cycles and mandated development to write quick readmes for every module or component. Eventually, it turned out that a quick bundling of these Readmes could provide a good enough narrative of the product functionalities and how to go about them. This drove the steady adoption of Markdown among the industry practitioners. The idea of continuous publishing, where a quick development fix and its parallel documentation could readily be made available, with minimum process overheads was too lofty an ideal to overlook.
Hence, it needs to be noted that DITA and Markdown are varied in their capabilities and reach. If the requirement is for a large enterprise with a broad spectrum of products, their variants, a swift growing corpus of information, multiple outputs, and a strong need for content reuse, DITA is the ideal choice. Markdown is best considered for products with a small documentation footprint. Markdown provides you the luxury of hitting the ground running while in a small team and catering to cloud-based products or small applications, but as your content needs grow over time, the necessity for content reuse and single-sourcing capabilities are impossible to overlook.
One Enterprise, but varied needs
Most companies launching cloud-based products were quick to adopt the Git-Markdown-HTML model of publishing. But this now posed a new challenge – what’s the approach if you are an enterprise where content has long been DITA-ised and you have an established pipeline that turns out PDFs and online help from DITA?
The challenges were multi-layered.
Multiple processes: The engineering teams used Git for version control and Markdown documents to factor in their feature updates, while the Technical Communication department had a DITA-PDF/DITA-Online Help publishing pipeline in place.
There was a need for the Technical Communications team to straddle the new engineering process and the existing doc process at the same time, as engineering was completely aligned to the Git-Markdown and Agile review process.
Availability of PDF: HTML did not conform to the enterprise-approved format of providing product information. For the customers, a PDF had to be available and the source files for these had to be in the version control, so the Technical Communication team had to convert the Markdown files to individual DITA/XML files.
Review process: Technical reviews were done using Git. This ensured faster turnaround and easier tracking of changes. The reviewed documents were then manually converted to DITA for renditions. The rendered DITA files had to go through the Acrolinx checks and subsequently, an editorial review, for which again, a PDF was mandatory. The final PDF further had to be approved by the product management and engineering teams.
The following diagram elucidates both of the processes in parallel. Git requires a new branch and a Pull Request for every Engineering Story, while the technical Communication pipeline requires the DITA content to be available in version control.
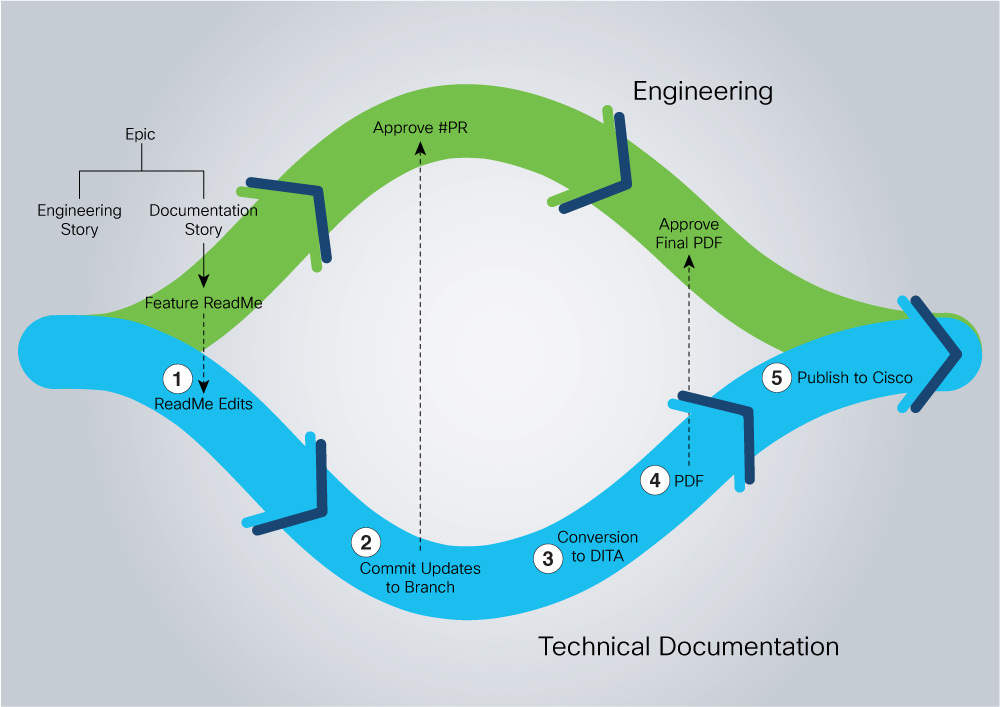
Challenges in Markdown vis-à-vis DITA
Though Markdown is much more lightweight than DITA in terms of syntax, it can turn out to be structurally different from a DITA-based Information Architecture model. And the difference arises because authoring in DITA is much more modular than in Markdown. A single Markdown file hence needs to be broken down into a number of DITA files – with different DTDs even.
The Markdown documents were subjected to technical reviews on Git. Once these were approved, the Technical Communication team did the Markdown-DITA conversion manually as the publishing framework uses DITA XML. The edits after editorial and final reviews were done on XML documentation. This resulted in differences in almost all published documents with respect to their markdown counterparts. Manually fixing the markdown documents would be duplicate work and a tedious effort. We tried to automate as much of the DITA to markdown conversion as possible using DITA Open Toolkit.
The need to synchronize the source
Post the migration of the content from MD to DITA and completing the final reviews on the PDF, the need was to synchronize the Development source with the updated content. This posed a challenge, for the following reasons:
- Lack of any good industry-accepted DITA – MD converters.
- The lack of full syntax support for DITA tags.
The Conversion
Following are the prerequisites:
- DITA-OT
- Notepad++
DITA to MD conversion
The following steps are on a Windows system. Note: There were some glitches while getting the Java libraries running successfully on Mac.
- Download and install DITA-OT
- Use the steps here: https://www.dita-ot.org/dev/topics/installing-client.html
- Download and install Notepad++
- Download the latest version of the Notepad++ installer from https://notepad-plus-plus.org/downloads/
- Run the executable binary and follow the installation wizard.
- Download the DITA files for the book.
- Download the DITA files from your version control. Ensure that you have chosen to download all the associated DITAMAPS, images, topics, and any other associated files.
- Extract the contents of the zip file.
Our version control system set the xml:lang parameter as en_US. DITA-OT does not recognize this. It uses en-US. We fix this in the next step. - Replace xml:lang=”en_US” with xml:lang=”en-US” in all the xml files.
- Open Notepad++
- Click the menu item Search > Find in Files or press Ctrl+Shift+F to search and replace in multiple files with one action.
- Set the base folder of the extracted bookmap zip file as a directory.
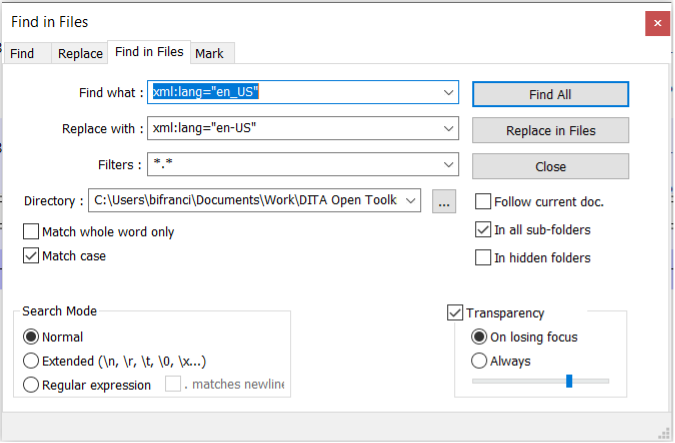
- In the Find what: textbox, enter xml:lang=”en_US”.
- In the Replace with: textbox, enter xml:lang=”en-US”.
- Check the In all sub-folders
- Click Replace in Files.
- Use DITA-OT to convert the DITAMAP to Markdown.
- In Windows Powershell, run: DITA-OT c:pwd> path/to/dita/bin/dita –input=path/to/bookmap/user-guide-20-x.ditamap –format=markdown_github, this script creates an out folder in the location you are running the command from. This folder contains the converted files. Note that the directory structure will be the same as how the DITAMAP and their associated topics, images, and other files existed in the version control.
- Edit index.md in the out folder using a text editor. You need to ensure that all the relatives paths to the topics from the DITAMAP are replaced with how the directories are placed in the Git directory. For example: – Change [Create New Users](../ topics/setting-up/config/c-create-new-users.md) in the index.md file to [Create New Users](td-xml/en_us/user-guide/topics/setting-up/config/c-create-new-users.md) as the ditamap file was located at td-xml/en_us/user-guide/bookmap.
Bottlenecks and other teething issues
The conversion was not entirely eventless. A manual clean-up of the tables was required, but this was expected, given the common knowledge that markdown does not support complex tables. The Technical Communication team had to manually check to ensure that all other aspects of the document were good – image references, formatting, links to other pages and other websites, and so on.
Challenges and learnings
It is essential to get a feature or a component-based review in MD and have it approved, but this does not provide the extended team with a larger picture of how the final PDF would look like. Over a few iterations, our observation was that the bulk of reviews happen only once the final PDF is available. And for making the PDF available, the shift from MD to DITA is inevitable. The idea of a content freeze before the MD-DITA conversion does look promising, but it might be difficult to get all of the stakeholders to agree.
There is the advantage of collective ownership from across multiple stakeholders, and besides, adopting the Git-Markdown process provided an added incentive of bringing in a prompt and more quick technical reviews, compared to the existing review pipeline. Git allowed easier co-authoring between the Technical Communication team and Development. This due to the fact that Git provides a framework to view delta changes to files, along with a seamless approval mechanism that is very developer-friendly. Tracing the evolution and dependencies of content and owners is never a bottleneck when on Git.